SurveyMonkey
통계적 유의성
통계적 유의성
여러 특정 응답 그룹 간에 설문조사 질문에 대한 답변 방식에 통계적 유의차가 있는지 확인할 수 있습니다. SurveyMonkey에서 통계적 유의성 기능을 사용하려면:
- 설문조사에서 질문에 비교 규칙을 추가하는 동시에 통계적 유의성 기능을 켭니다. 설문조사 결과를 그룹별로 나란히 비교하기 위해 비교하려는 그룹을 선택합니다.
- 설문조사에서 질문에 대한 데이터 표를 조사하여 여러 그룹 간에 설문조사 답변 방식에 통계적 유의차가 있는지 확인합니다.
통계적 유의성 보기
다음 단계에 따라 통계적 유의성을 표시할 수 있는 설문조사를 만들 수 있습니다.
- 1단계: 설문조사에 선택형 질문 추가
- 2단계: 응답 수집
- 3단계: 비교 규칙 적용
- 4단계: 데이터 표 조사
- 5단계: 결과 공유
설문조사 예
남성들이 여성들보다 귀사의 제품에 더 유의하게 만족해 하는지 확인해 보고자 합니다.
- 설문조사에 다음과 같은 객관식 질문 2개를 추가합니다.
• 귀하의 성별은 무엇입니까? (남성, 여성)
• 당사 제품에 얼마나 만족하십니까, 얼마나 불만족하십니까? (만족, 불만족) - 성별에서 남성을 선택한 응답자가 30명 이상이고 여성을 선택한 응답자가 30명 이상이어야 합니다.
- 귀하의 성별은 무엇입니까? 질문에 비교 규칙을 추가하고 남성과 여성 보기를 모두 그룹으로 선택합니다.
- 당사 제품에 얼마나 만족하거나 불만족하십니까?의 질문 차트 아래에 있는 데이터 표를 사용하여 보기가 유의차를 표시하는지 확인합니다.
통계적 유의차란?
통계적 유의차는 통계적 검정을 사용해 한 그룹의 답변이 다른 그룹의 답변과 현저히 다른지의 여부를 나타냅니다. 통계적 유의성은 해당 수치가 확실히 다르다는 것을 의미하므로 데이터 분석에 상당히 유용합니다. 하지만, 결과가 중요한지 여부를 고려해야 합니다. 즉, 결과를 해석하는 방식이나 결과에 대해 조치를 취하는 방식을 결정하는 것은 회원님의 몫입니다.
예를 들어, 남성보다 여성에게 더 많은 고객 불만을 받고 있다고 가정해 보겠습니다. 이것이 처리해야 하는 실제 차이인지 어떻게 알 수 있을까요? 가장 좋은 방법은 남성 고객이 귀사의 제품에 훨씬 더 만족하고 있는지 확인하는 설문조사를 진행하는 것입니다. 통계식을 사용하는 SurveyMonkey의 통계적 유의성 기능을 통해 남성이 여성보다 귀사 제품에 대한 만족도가 유의하게 높은지 확인할 수 있습니다. 따라서 한 가지 측면만 보지 않고 이 데이터를 토대로 조치를 취할 수 있습니다.
- 통계적 유의차
- 통계적 유의차 없음
- 표본 크기
통계적 유의성 계산
표준 95% 신뢰 수준을 사용해 통계적 유의성을 계산합니다. 보기를 통계적으로 유의하다고 표시할 때 두 그룹 간 차이가 우연히 또는 표본 추출 오차 단독으로 발생할 확률은 5% 미만이므로, 흔히 p < 0.05로 표시됩니다.
그룹 간의 통계적 유의성을 계산하기 위해 다음 공식을 사용합니다.
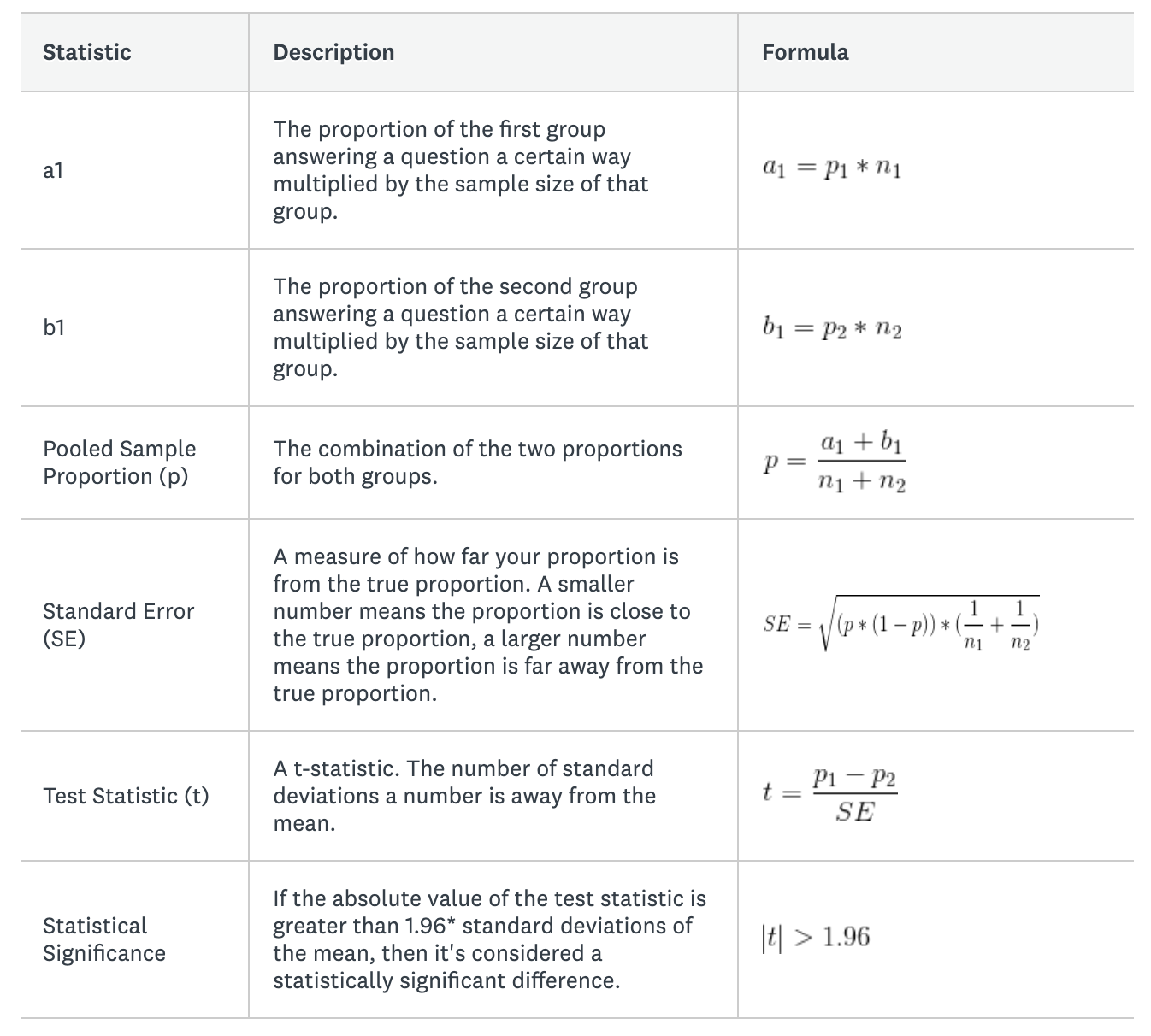
*교과서에 나오는 t-분포 함수에서 95%의 면적이 평균의 표준 편차 1.96 내에 있기 때문에 1.96은 95% 신뢰 수준에서 사용되는 수치입니다.
계산 예
위의 예를 계속 진행해 보면서 귀사의 제품에 만족한다고 대답한 남성의 비율이 여성의 비율보다 유의하게 더 많은지 확인해 보겠습니다.
남성 1000명과 여성 1000명을 대상으로 설문조사를 실시했고 여성이 65%인데 비해 남성 70%가 귀사의 제품에 만족한다고 대답했다고 가정해 보겠습니다. 70%가 65%보다 유의하게 더 높습니까?
다음 설문조사 데이터를 사용해 공식을 완성합니다.
- p1(제품에 만족한 남성 비율[%]) = 0.7
- p2(제품에 만족한 여성 비율[%]) = 0.65
- n1(설문조사 대상 남성 수) = 1000명
- n2(설문조사 대상 여성 수) = 1000명

검정 통계량의 값이 1.96보다 크기 때문에, 이것은 여성과 남성 간의 차이가 유의함을 의미합니다. 남성이 여성보다 귀사의 제품에 만족할 가능성이 더 높습니다.
통계적 유의성 숨기기
모든 질문에서 통계적 유의성을 숨기려면:
- 왼쪽 사이드바에서 비교 규칙의 오른쪽에 있는 아래쪽 화살표를 클릭합니다.
- 규칙 수정을 클릭합니다.
- 통계적 유의성 표시 옆에 있는 토글을 클릭하여 끕니다.
- 적용을 클릭합니다.
한 개의 질문에서 통계적 유의성을 숨기려면:
- 질문 차트 위에 있는 맞춤 조정을 클릭합니다.
- 표시 옵션 탭을 클릭합니다.
- 통계적 유의성 옆 확인란의 선택을 취소합니다.
- 저장을 클릭합니다.
통계적 유의성을 표시하면 행과 열 바꾸기 표시 옵션이 자동으로 켜집니다. 이 표시 옵션의 선택을 취소하면, 통계적 유의성 기능도 꺼집니다.